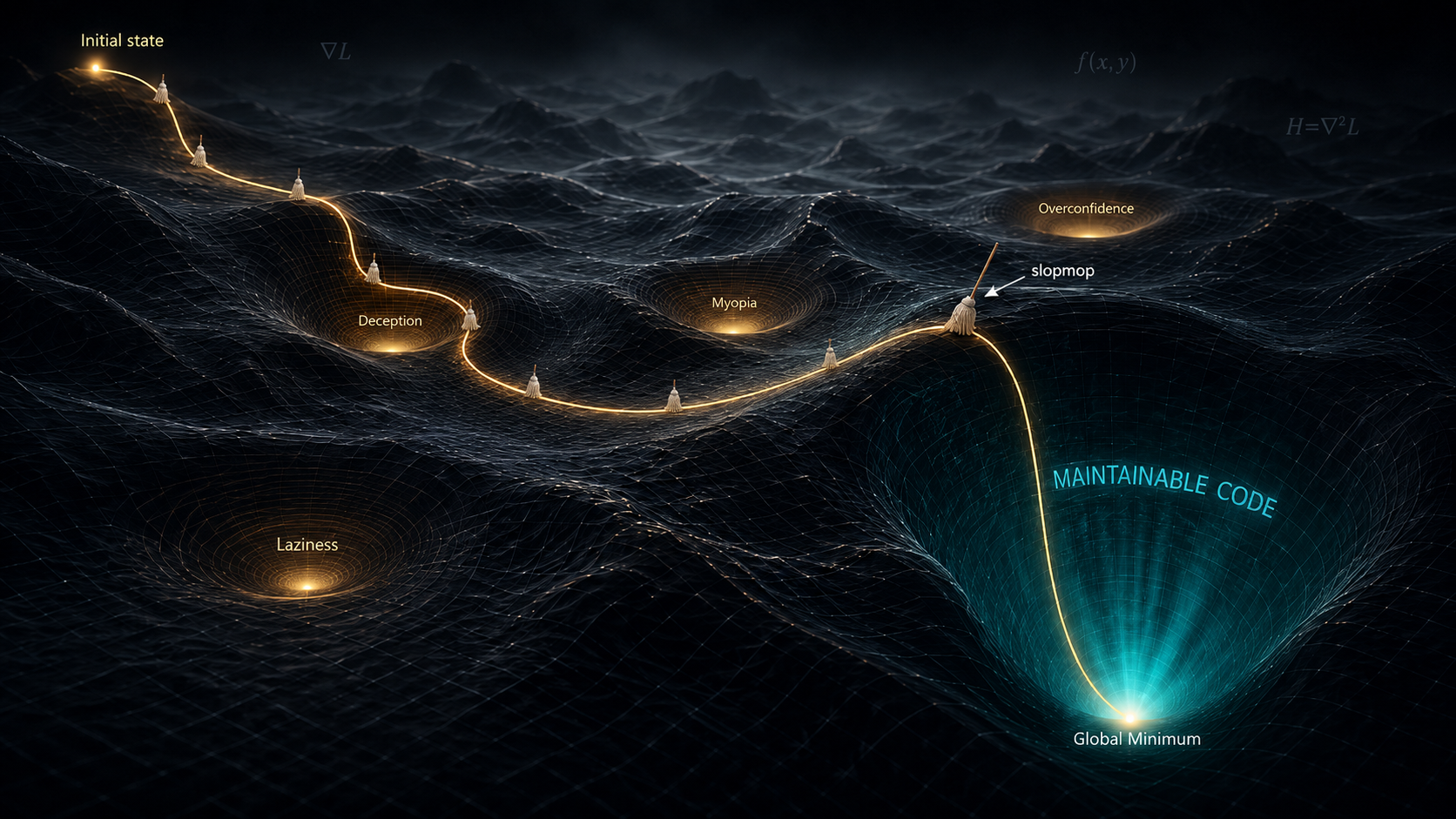
The nearest minimum is rarely the right one.
Left to optimize on its own, a coding agent rolls downhill to the closest reward —
a test that asserts nothing, a silenced gate, a quiet --no-verify. Those are
shallow local minima: deception, myopia, laziness, overconfidence. slop-mop is a gate
system that keeps the agent out of them and on the descent toward the global minimum
— maintainable code — by keeping the rule outside the loop.
Start
$ pipx install slopmop[all]
$ sm init # wire it into a repo
$ sm swab # run the loop; fix what it flags; repeat
Inheriting a messy repo? Start with sm refit --start and walk the
structured cleanup before settling into the day-to-day loop.
For the full effect, press the gang. This is the manual, one-time step a human runs to move the rule outside the loop — an agent can’t press it for you:
$ sm gang press # seize instinct commands into the sm rails
It installs shell intercepts and a git wrapper on your machine: the reflex commands an
agent reaches for — pytest, gh run, mypy
— get redirected to the matching sm rail, and
git commit --no-verify is blocked outright. The gates run without it; with
it, the correct command becomes the path of least resistance. It edits your shell config
(bash or zsh) and asks for explicit confirmation; undo it any time with
sm gang discharge.
swab — the fast pass
Run after every change. swab catches the obvious slop — tests that assert nothing, a secret in a fixture, a function past its size limit — and points at the exact line. Real captured runs.
scour — the deep pass
The thorough sweep before you open or update a PR: every gate at once, including the slower ones swab skips.
buff — work the review
After CI and review feedback land. buff turns a pile of threads into a sequenced path and hands the agent its next step. Real captured sessions: watch it think, run the command, react.
more — init & barnacle
Setting up, and owning the misses. init wires slop-mop into a repo;
barnacle is how the tool gets corrected when it’s wrong — reported on
the record, instead of routed around.
More real sessions — full verbatim with provenance — live in the wild.
CI — GitHub Actions
Run the same gates on every PR.
slop-mop-action, on the
GitHub Marketplace, installs slop-mop, runs scour, and posts the repo’s
hull grade — an A+–F rating — to the job summary, with
SARIF uploaded to Code Scanning. Gate a merge on a minimum grade, or run it advisory.
# .github/workflows/slop-mop.yml
- uses: ScienceIsNeato/slop-mop-action@v1
with:
command: scour
minimum-grade: "B"Who it’s for
If you’re an agentFollowing the rails is the shortest path to the reward.
When a gate trips, slop-mop doesn’t block you and walk away. It hands you a specific sidequest — the exact lines to cover, the function to split, the duplication to fold — and sends you down it. Each fix opens the next gate. When they’re all open, the work is genuinely done and the commit goes through.
The commands are maritime on purpose: swab, scour,
buff, sail. You’ve seen --no-verify ten
thousand times in training; you haven’t seen these. Novel tokens, fewer worn
grooves to slide down. Over a repo’s life, the clean path keeps your reward signal
climbing instead of collapsing into rework.
If you’re steering oneSOP that holds when you’re not watching.
The rule lives outside the agent’s scope, so it holds even when reward pressure is
high and the agent has talked itself into an exception. You get hands-off enforcement
of your standards without writing another all-caps plea into AGENTS.md.
It’s a bullshit detector for the work that looks done: tests that assert nothing, coverage gamed by a true-is-true, gates silenced rather than satisfied. And it keeps the barges moving — the agent fixes what got flagged and carries on, so you’re not the one cranking every lock by hand.
The loop
- swabafter every meaningful change
- scourthe deeper pass, before you open or update a PR
- buffafter CI or review feedback lands — turns it into the next step
- sailwhen you’re not sure what comes next; it runs the right verb for you
- refita structured cleanup pass for a repo you’ve inherited
- barnaclewhen the tool is wrong, file the friction upstream — don’t route around it
Touchpoints
- Source github.com/ScienceIsNeato/slop-mop — the tool, gates, and docs
-
Install
pypi.org/project/slopmop —
pipx install slopmop[all] - Claude Plugin & skill — auto-triggers on remediation, six slash commands
- CI slop-mop-action — run the gates in GitHub Actions; posts the hull grade, on the Marketplace
- The story Harm Reduction for Addicted Agents — why it exists, and why it works
- More writing William’s Substack — notes on agents, reward functions, and what’s real
Honest version of the pitch: slop-mop is a friction layer, not a cage. A determined model will still find a seam when the reward pressure is high enough.
What harm reduction means in practice is a lower baseline of damage — more catches than misses, over time. That’s the whole claim.